Cluster of computers

Before We start
It’s totally theoritical I have no practical experience in this topic. I want that(practical experience) that’s why I am writing this blog 😉 . And I am totally copying the content of this blog from Hadoop Documentation.
I just googled this “ HDFS relaxes a few POSIX requirements to enable streaming access to file system data “
You will find tons of link, You can accuse them of plagiarism, Mine as well.
Let’s start
What is HDFS ?
The Hadoop Distributed File System (HDFS) is a distributed file system. So what is a distributed file system. Your file data will be present on multiple system.
HDFS is built,ok, But what is the use case ?
- Hardware Failure -> HDFS is designed to built on cheap commodity hardware. So this means you cannot run it on Good Hardware. Nope, you will just incur more cost.
- Streaming Data Access -> High data throughput rates. What is throughput. Maximum rate at which data can be processed.
- Large Data Sets -> Tuned to support large files.
- Simple Coherencey model -> Write once read many . But what is coherency.All copies of on data set include always the same data values.
- Moving Computation is Cheaper than Moving Data -> Do calcultion on machine near where is data is stored.
- Portability Across Heterogeneous Hardware and Software Platforms -> Self descriptive.
NameNode and Datanodes.
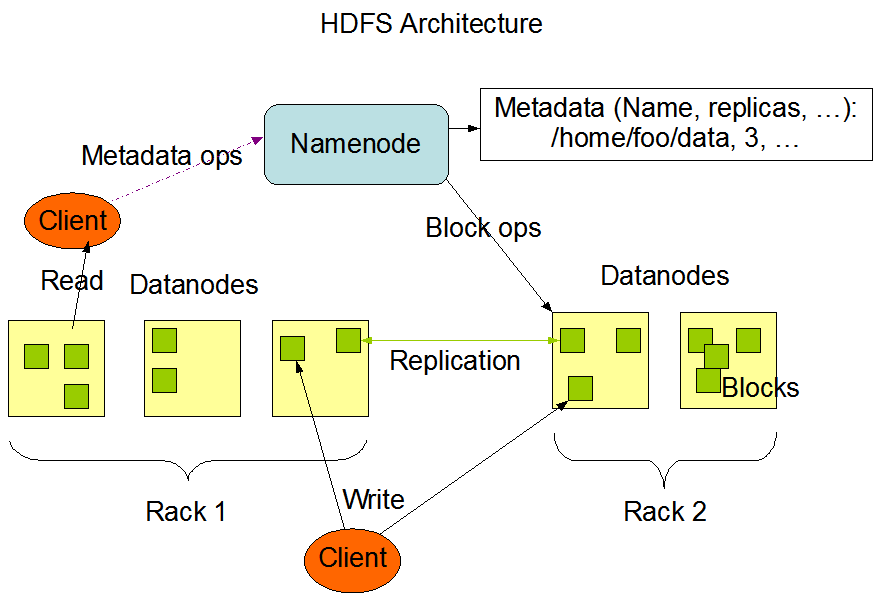
What is a Namenode ?
NameNode -> NameNode is a master server that manages the file system namespace and regulates access to files by clients. It feels similar to loadbalancer. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. Data never flows through NameNode.
Data replication
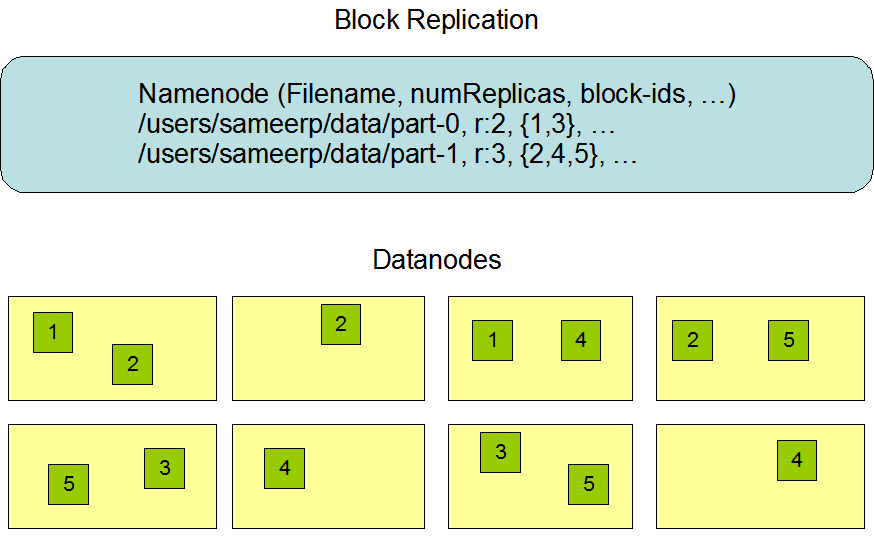 HDFS stores each file as a sequence of block. There are replicated as well, All blocks except the last one are of same size. An application can support number of number of replicas of a file. An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later. Files in HDFS are write-once (except for appends and truncates) and have strictly one writer at any time.
HDFS stores each file as a sequence of block. There are replicated as well, All blocks except the last one are of same size. An application can support number of number of replicas of a file. An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later. Files in HDFS are write-once (except for appends and truncates) and have strictly one writer at any time.Replica Placement.
Rack-aware replica placement policy is to improve data reliability, availability, and network bandwidth utilization. The NameNode determines the rack id each DataNode belongs to via the process outlined in Hadoop Rack Awareness. A simple but non-optimal policy is to place replicas on unique racks. This prevents losing data when an entire rack fails and allows use of bandwidth from multiple racks when reading data. This policy evenly distributes replicas in the cluster which makes it easy to balance load on component failure. However, this policy increases the cost of writes because a write needs to transfer blocks to multiple racks.If the replication factor is greater than 3, the placement of the 4th and following replicas are determined randomly while keeping the number of replicas per rack below the upper limit (which is basically (replicas - 1) / racks + 2).
Replica Selection
Datanodes can be distributed across multiple regions. So replica selection for user is done which datanode is nearest to him.
Communication protocol
Just like HTTP all the communication b/w nodes is based on TCP/IP. A client connects with NameNode machine. It talks the ClientProtocol with the NameNode. The DataNodes talk to the NameNode using the DataNode Protocol. The DataNodes talk to the NameNode using the DataNode Protocol. A Remote Procedure Call RPC abstraction wraps both the Client Protocol and the DataNode Protocol. By design, the NameNode never initiates any RPCs. It only responds to RPC requests by DataNodes or clients.
Data Disk Failure, Heartbeats and Re-Replication
- DataNode sends a Heartbeat message to the NameNode
- NameNode detects this condition by the absence of a Heartbeat message
- NameNode marks DataNodes without recent Heartbeats as dead
- DataNode death may cause the replication factor of some blocks to fall, The NameNode constantly tracks which blocks need to be replicated and initiates replication whenever necessary.
- The time-out to mark DataNodes dead is conservatively long (over 10 minutes by default) in order to avoid replication storm caused by state flapping of DataNodes
Cluster Rebalancing
- There is a data rebalancing scheme
- It can move data from one DataNode to another if the free space on a DataNode falls below a certain threshold
- In the event of a sudden high demand for a particular file, a scheme might dynamically create additional replicas and rebalance other data in the cluster
Not yet implemented(Seriously). Might be good intern work. LOL
Data integrity
- HDFS client software implements checksum checking on the contents of HDFS files
- A client creates an HDFS file, it computes a checksum of each block of the file and stores these checksums in a separate hidden file in the same HDFS namespace.
Metadata Disk Failure
- FsImage and the EditLog are central data structures of HDFS
- So NameNode can be configured to support maintaining multiple copies of the FsImage and EditLog
- Synchronous updating of multiple copies of the FsImage and EditLog may degrade the rate of namespace transactions per second that a NameNode can support.
- When a NameNode restarts, it selects the latest consistent FsImage and EditLog to use
- Another option to increase resilience against failures is to enable High Availability using multiple NameNodes either with a shared storage on NFS or using a distributed edit log
Snapshots
- Similar to git commit
What happens when you decrease replication factor ?
When the replication factor of a file is reduced, the NameNode selects excess replicas that can be deleted. The next Heartbeat transfers this information to the DataNode.
Features in HDFS
- File permissions and authentication.
- Rack awareness: to take a node’s physical location into account while scheduling tasks and allocating storage.
- Safemode: an administrative mode for maintenance.
- fsck: a utility to diagnose health of the file system, to find missing files or blocks.
- fetchdt: a utility to fetch DelegationToken and store it in a file on the local system.
- Balancer: tool to balance the cluster when the data is unevenly distributed among DataNodes.
- Upgrade and rollback: after a software upgrade, it is possible to rollback to HDFS’ state before the upgrade in case of unexpected problems.
- Secondary NameNode: performs periodic checkpoints of the namespace and helps keep the size of file containing log of HDFS modifications within certain limits at the NameNode.
- Checkpoint node: performs periodic checkpoints of the namespace and helps minimize the size of the log stored at the NameNode containing changes to the HDFS. Replaces the role previously filled by the Secondary NameNode, though is not yet battle hardened. The NameNode allows multiple Checkpoint nodes simultaneously, as long as there are no Backup nodes registered with the system.
- Backup node: An extension to the Checkpoint node. In addition to checkpointing it also receives a stream of edits from the NameNode and maintains its own in-memory copy of the namespace, which is always in sync with the active NameNode namespace state. Only one Backup node may be registered with the NameNode at once.
- Checkpoint and Backup Node in detail
Commands in HDFS
All commands start with hdfs:
| Commands | Description |
|---|---|
| fs –help ls | lists the usage information along with the options to use the command |
| fs –ls –R /user/username | Returns all the available files and recursively lists all the subdirectories under /user/username |
| fs –mkdir /user/username/directory-name | create a new directory |
| fs –copyFromLocal Sample1.txt /user/username/destination-address | copy from local filesystem to hdfs |
| fs –put Sample2.txt /user/username/destination-address | uploads a single file or multiple source files from local file system to hadoop distributed file system |
| fs –moveFromLocal Sample1.txt /user/username/destination-address | deletes original and copy |
| fs –du /user/username/destination-address | HDFS disk usage command |
| fs –df | Display disk usage of current hadoop distributed file system |
| fs –expunge | empties the trash by deleting all the files and directories |
There a lot of other command similar to unix file system with hadoop fs prefixed.
Command prefix “hdfs “:
| Commands | Description |
|---|---|
| classpath –glob | expands wildcard I don’t know what that is |
| classpath –jar | write classpath as manifest in jar named path |
| classpath -h | print help |
It checks file system integrity
Command prefix “hdfs fcsk “:
| Commands | Description |
|---|---|
| -delete | Delete corrupted files. |
| -files | Print out files being checked. |
| -files -blocks | Print out the block report |
| -files -blocks -locations | Print out locations for every block. |
| -files -blocks -racks | Print out network topology for data-node locations. |
| -files -blocks -replicaDetails | Print out each replica details. |
| -files -blocks -upgradedomains | Print out upgrade domains for every block. |
| -includeSnapshots | Include snapshot data if the given path indicates a snapshottable directory or there are snapshottable directories under it. |
| -list-corruptfileblocks | Print out list of missing blocks and files they belong to. |
| -move | Move corrupted files to /lost+found. |
| -openforwrite | Print out files opened for write. |
| -storagepolicies | Print out storage policy summary for the blocks. |
| -maintenance | Print out maintenance state node details. |
| -blockId | Print out information about the block. |
prefix hdfs getconf:
| Commands | Description |
|---|---|
| -namenodes | gets list of namenodes in the cluster. |
| -secondaryNameNodes | gets list of secondary namenodes in the cluster. |
| -backupNodes | gets list of backup nodes in the cluster. |
| -includeFile | gets the include file path that defines the datanodes that can join the cluster. |
| -excludeFile | gets the exclude file path that defines the datanodes that need to decommissioned. |
| -nnRpcAddresses | gets the namenode rpc addresses |
| -confKey key | gets a specific key from the configuration |
prefix hdfs groups: | Commands | Description | | :—— | :———————– | | username | Returns the group information given one or more usernames. |
prefix hdfs balancer:
| Commands | Description |
|---|---|
| -policy policy | datanode (default): Cluster is balanced if each datanode is balanced.blockpool: Cluster is balanced if each block pool in each datanode is balanced. |
| -threshold threshold | Percentage of disk capacity. This overwrites the default threshold. |
| -exclude -f hosts-file comma-separated list of hosts | Excludes the specified datanodes from being balanced by the balancer. |
| -include -f |
Includes only the specified datanodes to be balanced by the balancer. |
| -source -f |
Pick only the specified datanodes as source nodes. |
| -blockpools comma-separated list of blockpool ids | The balancer will only run on blockpools included in this list. |
| -idleiterations |
Maximum number of idle iterations before exit. This overwrites the default idleiterations(5). |
| -runDuringUpgrade | Whether to run the balancer during an ongoing HDFS upgrade. This is usually not desired since it will not affect used space on over-utilized machines. |
| -h | Display the tool usage and help information and exit. |
Generic options
Prefix hdfs :
| Commands | Description |
|---|---|
| -archives comma separated list of archives | Specify comma separated archives to be unarchived on the compute machines. Applies only to job. |
| -conf configuration file | Specify an application configuration file. |
| -D property=value | Use value for given property. |
| -files comma separated list of files | Specify comma separated files to be copied to the map reduce cluster. Applies only to job. |
| -fs file:/// or hdfs://namenode:port | Specify default filesystem URL to use. Overrides ‘fs.defaultFS’ property from configurations. |
| -jt local or resourcemanager:port | Specify a ResourceManager. Applies only to job. |
| -libjars comma seperated list of jars | Specify comma separated jar files to include in the classpath. Applies only to job. |
See more
Cacheadmin
- hdfs cacheadmin [-addDirective -path
-pool [-force] [-replication ] [-ttl ]] - hdfs cacheadmin [-modifyDirective -id
[-path ] [-force] [-replication ] [-pool ] [-ttl ]] - hdfs cacheadmin [-listDirectives [-stats] [-path
] [-pool ] [-id ]] - hdfs cacheadmin [-removeDirective
] - hdfs cacheadmin [-removeDirectives -path
] - hdfs cacheadmin [-addPool
[-owner ] [-group ] [-mode ] [-limit ] [-maxTtl ]] - hdfs cacheadmin [-modifyPool
[-owner ] [-group ] [-mode ] [-limit ] [-maxTtl ]] - hdfs cacheadmin [-removePool
] - hdfs cacheadmin [-listPools [-stats] [
]] - hdfs cacheadmin [-help
]
HDFS High Availability Using the Quorum Journal Manager
What is the usecase ?
Prior to Hadoop 2.0.0, the NameNode was a single point of failure (SPOF) in an HDFS cluster. Each cluster had a single NameNode, and if that machine or process became unavailable, the cluster as a whole would be unavailable until the NameNode was either restarted or brought up on a separate machine.
Architecture
In a typical HA cluster, two separate machines are configured as NameNodes. At any point in time, exactly one of the NameNodes is in an Active state, and the other is in a Standby state. The Active NameNode is responsible for all client operations in the cluster, while the Standby is simply acting as a slave, maintaining enough state to provide a fast failover if necessary.
- In order for the Standby node to keep its state synchronized with the Active node, both nodes communicate with a group of separate daemons called “JournalNodes” (JNs). When any namespace modification is performed by the Active node
- The Standby node is capable of reading the edits from the JNs, and is constantly watching them for changes to the edit log
- As the Standby Node sees the edits, it applies them to its own namespace
- It is vital for the correct operation of an HA cluster that only one of the NameNodes be Active at a time. Otherwise, the namespace state would quickly diverge between the two, risking data loss or other incorrect results. In order to ensure this property and prevent the so-called “split-brain scenario,” the JournalNodes will only ever allow a single NameNode to be a writer at a time
- Will Not type of different config files.
HDFS Federation
Federation in Hadoop uses multiple independent Namenode/namespaces to scale the name service horizontally. In HDFS Federation Architecture, at the bottom, datanodes are present. And datanodes are used as common storage for blocks by all the namenodes. Each datanodes registers with all the namenodes in the cluster. These datanodes send periodic heartbeats, block report and handle command from the namenodes
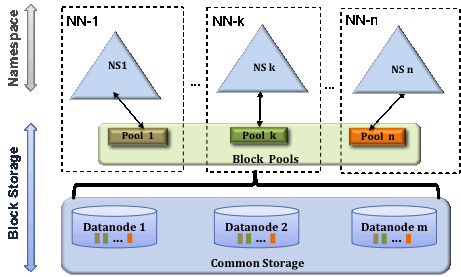
Block Pool
A Block Pool is a set of blocks that belong to a single namespace. Datanodes store blocks for all the block pools in the cluster. Each Block Pool is managed independently. This allows a namespace to generate Block IDs for new blocks without the need for coordination with the other namespaces
ClusterID
A ClusterID identifier is used to identify all the nodes in the cluster. When a Namenode is formatted, this identifier is either provided or auto generated. In detail about config