General Architecture

Before We start
It’s totally theoritical I have no practical experience in this topic. I want that(practical experience) that’s why I am writing this blog 😉 . I am copying content from various sources which I have read and experimented in the last week.
Installation
This [link] works totally fine. Except the download link Use this link to download hadoop instead [link] .Few pointers for misery I faced:
- OpenJdk doesn’t work properly with hadoop. After a day’s effort I realized that my node and resource manager is not working due to OpenJdk. I changed it to oracle 8 and then it works properly. I even disabled firewall even then it didn’t work.
- Make a new user or it will give some root error.
- Take care of version in hadoop what solution and configuration is provided for 2.0 may not work for versions > 3.
MapReduce
All moving parts
- A MapReduce job usually splits the input data-set into independent chunks
- The MapReduce framework consists of a single master ResourceManager
- One worker NodeManager per cluster-node.
What is comprised in job configuration ?
- the input/output locations
- supply map and reduce functions
The Hadoop job client then submits the job (jar/executable etc.) and configuration to the ResourceManager which then distributes software to the workers, scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
Understanding Word count from different perspectives.
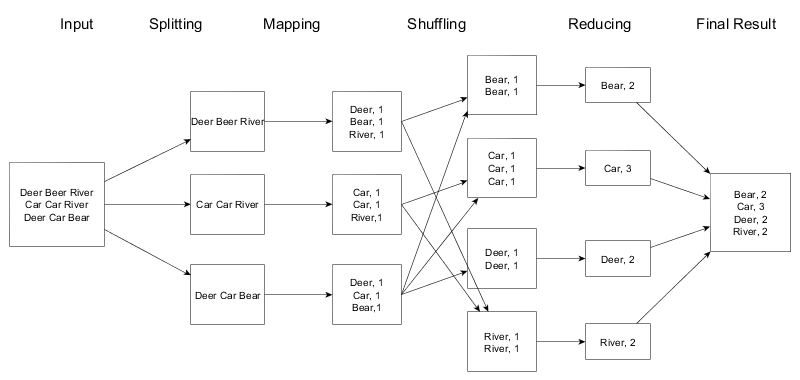 Code Walkthrough
Code Walkthrough
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
The variables one and word are the key/value pair respectively.
StringTokenizer itr = new StringTokenizer(value.toString());
It splits the line into tokens separated by whitespaces, via the StringTokenizer, and emits a key-value pair of <
1
2
3
4
5
6
7
8
9
10
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
I found this loop amusing so I googled it and it means(enhanced for)
for(int i = 0; i < values.size(); i++) {
sum += val.get(i);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
This is used to set different configuration of a job.[ref]
Payload
 Mapper
Mapper
- Maps are the individual tasks that transform input records into intermediate records.
- Spawns one map task for each InputSplit generated by the InputFormat for the job.
- Users can control the grouping by specifying a Comparator via Job.setGroupingComparatorClass(Class).
- Users can control which keys (and hence records) go to which Reducer by implementing a custom Partitioner.
- The intermediate, sorted outputs are always stored in a simple (key-len, key, value-len, value) format. Applications can control if, and how, the intermediate outputs are to be compressed and the CompressionCodec to be used via the Configuration.
FileOutputFormat.setCompressOutput(job, true); FileOutputFormat.setOutputCompressorClass(job, org.apache.hadoop.io.compress.SnappyCodec.class); - For more information visit ref
No of Maps
job.set(MRJobConfig.NUM_MAPS, int) according to the previous code.
Reducer
The number of reduces for the job is set by the user via Job.setNumReduceTasks(int). Reducer has 3 primary phases: shuffle, sort and reduce.The output of the reduce task is typically written to the FileSystem via Context.write(WritableComparable, Writable).
Secondary Sort
If equivalence rules for grouping the intermediate keys are required to be different from those for grouping keys before reduction, then one may specify a Comparator via Job.setSortComparatorClass(Class). Since Job.setGroupingComparatorClass(Class) can be used to control how intermediate keys are grouped, these can be used in conjunction to simulate secondary sort on values.
Task Execution & Environment
The MRAppMaster executes the Mapper/Reducer task as a child process in a separate jvm.The child-task inherits the environment of the parent MRAppMaster.Ref
Memory management
- Can specify the maximum virtual memory of the launched child-task, and any sub-process it launches recursively.
- Basic Ref
Map and Reduce parameters
Map parameters
| Name | Type | Description |
|---|---|---|
| mapreduce.task.io.sort.mb | int | The cumulative size of the serialization and accounting buffers storing records emitted from the map, in megabytes. |
| mapreduce.map.sort.spill.percent | float | The soft limit in the serialization buffer. Once reached, a thread will begin to spill the contents to disk in the background. |
Similarly there are reduce parameters.Ref
Logs
The standard output (stdout) and error (stderr) streams and the syslog of the task are read by the NodeManager and logged to ${HADOOP_LOG_DIR}/userlogs.
Job control
This is an important concept. Users may need to chain MapReduce jobs to accomplish complex tasks which cannot be done via a single MapReduce job. This is fairly easy since the output of the job typically goes to distributed file-system, and the output, in turn, can be used as the input for the next job.
- Job.submit() : Submit the job to the cluster and return immediately.
- Job.waitForCompletion(boolean) : Submit the job to the cluster and wait for it to finish.
Ref
Job input
InputFormat describes the input-specification for a MapReduce job.The MapReduce framework relies on the InputFormat of the job to:
- Validate the input-specification of the job.
- Split-up the input file(s) into logical InputSplit instances, each of which is then assigned to an individual Mapper.
- Provide the RecordReader implementation used to glean input records from the logical InputSplit for processing by the Mapper.
InputSplit - InputSplit represents the data to be processed by an individual Mapper.
- FileSplit is the default InputSplit. It sets mapreduce.map.input.file to the path of the input file for the logical split.
RecordReader - RecordReader reads <key, value> pairs from an InputSplit.
This Job input topic is not very clear to me yet.
Task Side-Effect Files.
In some applications, component tasks need to create and/or write to side-files, which differ from the actual job-output files. So this manages how the file will be saved and all that.
Submitting jobs to queues.
-
Queues, as collection of jobs, allow the system to provide specific functionality.Hadoop comes configured with a single mandatory queue, called ‘default’. Queue names are defined in the mapreduce.job.queuename property of the Hadoop site configuration. Some job schedulers, such as the Capacity Scheduler, support multiple queues.
-
A job defines the queue it needs to be submitted to through the mapreduce.job.queuename property, or through the Configuration.set(MRJobConfig.QUEUE_NAME, String) API. Setting the queue name is optional. If a job is submitted without an associated queue name, it is submitted to the ‘default’ queue.
Distributed Cache
- DistributedCache distributes application-specific, large, read-only files efficiently.
- Applications specify the files to be cached via urls (hdfs://) in the Job. The DistributedCache assumes that the files specified via hdfs:// urls are already present on the FileSystem.
- The files/archives can be distributed by setting the property mapreduce.job.cache.{files or archives}. If more than one file/archive has to be distributed, they can be added as comma separated paths. The properties can also be set by APIs Job.addCacheFile(URI)/ Job.addCacheArchive(URI) and Job.setCacheFiles(URI[])/ Job.setCacheArchives(URI[]) where URI is of the form hdfs://host:port/absolute-path#link-name.
- In Streaming, the files can be distributed through command line option -cacheFile/-cacheArchive.
Profiling
- User can specify whether the system should collect profiler information for some of the tasks in the job by setting the configuration property mapreduce.task.profile.
- The value can be set using the api Configuration.set(MRJobConfig.TASK_PROFILE, boolean). If the value is set true, the task profiling is enabled.
Debugging
The MapReduce framework provides a facility to run user-provided scripts for debugging.
- The user needs to use DistributedCache to distribute and symlink to the script file.
- Set values for the properties mapreduce.map.debug.script and mapreduce.reduce.debug.script, for debugging map and reduce tasks respectively. These properties can also be set by using APIs Configuration.set(MRJobConfig.MAP_DEBUG_SCRIPT, String) and Configuration.set(MRJobConfig.REDUCE_DEBUG_SCRIPT, String).
Note
- You can run python and c code as job in hadoop as well.
- There are go wrapper as well for hadoop.