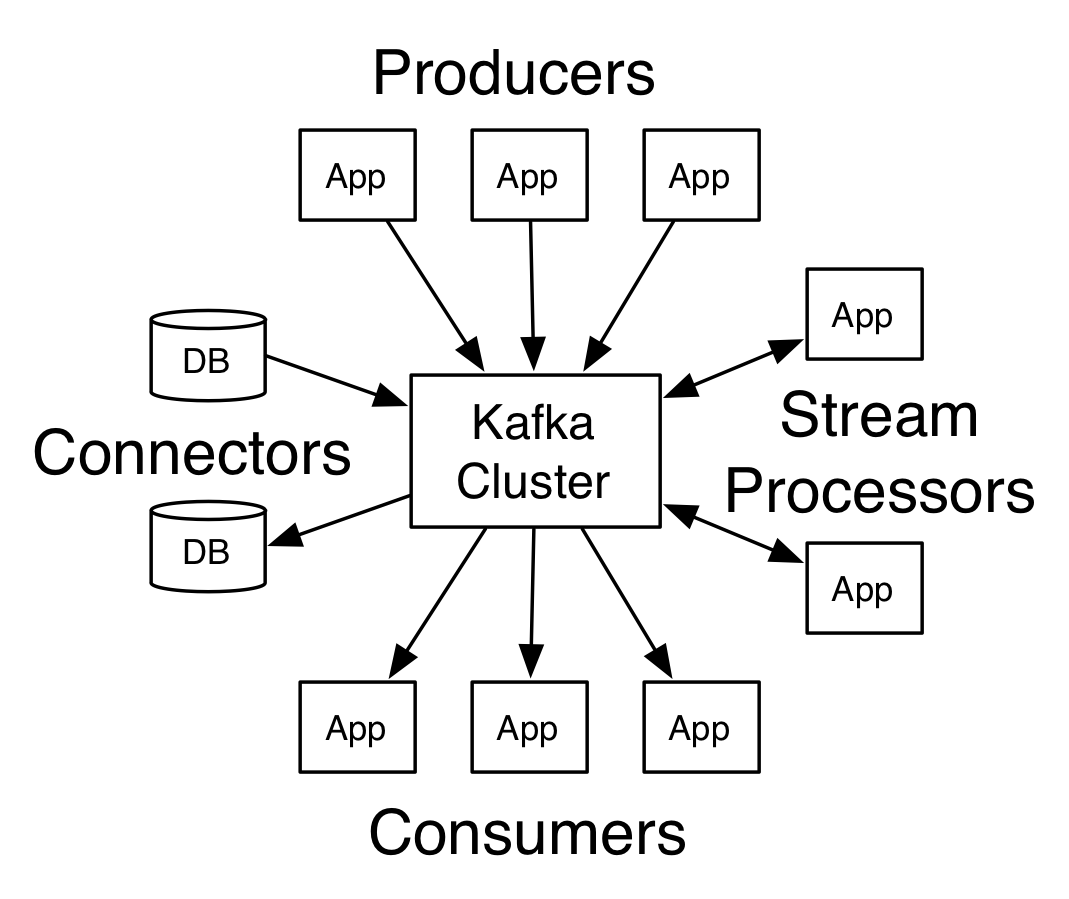
General Architecture
Before We start
It’s totally theoritical I have no practical experience in this topic. I want that(practical experience) that’s why I am writing this blog 😉 . I will be copying the whole content from official documentation.
Let’s start
Kafka has three main components->
- A Producer: The service that emits the source data.
- A Broker: Kafka acts as an intermediary between the producer and the consumer. It uses the power of API’s to get and broadcast data
- A Consumer: The service that uses the data which the broker will broadcast.
API’S
- Consumer API->allows an application to publish a stream of records to one or more Kafka topics
- Producer API->allows an application to subscribe to one or more topics and process the stream of records produced to them
- Streams API->allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics
- Connector API->allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
The architecture seems a mix of ROS and Model View Controller architecture.
Topic
A topic is a name to which data are being published. For each topic, the Kafka cluster maintains a partitioned log that looks like this:
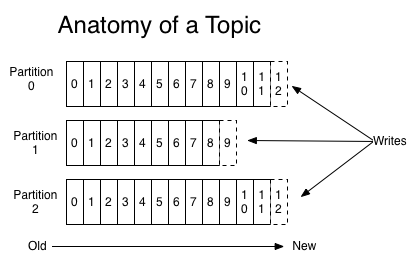 partition is an ordered, immutable sequence of records that is continually appended to.Kafka cluster durably persists all published records—whether or not they have been consumed—using a configurable retention period. Only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. A consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from “now”.
partition is an ordered, immutable sequence of records that is continually appended to.Kafka cluster durably persists all published records—whether or not they have been consumed—using a configurable retention period. Only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. A consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from “now”.
Why partition ?
They allow the log to scale beyond a size that will fit on a single server. The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions.Each partition has one server which acts as the “leader” and zero or more servers which act as “followers”. The leader handles all read and write requests for the partition while the followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
Producer
The producer is responsible for choosing which record to assign to which partition within the topic.
Consumer
Consumers label themselves with a consumer group name(similar to access control list).
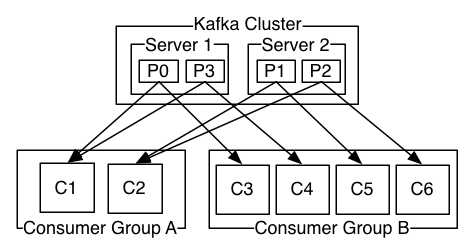 The Consumer API allows applications to read streams of data from topics in the Kafka cluster.
The Consumer API allows applications to read streams of data from topics in the Kafka cluster.
Multi Tenancy
You can deploy Kafka as a multi-tenant solution. Multi-tenancy is enabled by configuring which topics can produce or consume data. What is tenancy -> (“software multitenancy” refers to a software architecture in which a single instance of software runs on a server and serves multiple tenants. A tenant is a group of users who share a common access with specific privileges to the software instance.) Administrators can define and enforce quotas on requests to control the broker resources that are used by clients.
Class KafkaProducer
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "my-transactional-id");
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
producer.initTransactions();
try {
producer.beginTransaction();
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
producer.abortTransaction();
}
producer.close();
There can be only one open transaction per producer. All messages sent between the beginTransaction() and commitTransaction() calls will be part of a single transaction. When the transactional.id is specified, all messages sent by the producer must be part of a transaction. the send call is asynchronous it returns a Future for the RecordMetadata that will be assigned to this record. Invoking get() on this future will block until the associated request completes and then return the metadata for the record or throw any exception that occurred while sending the record.If you want to simulate a simple blocking call you can call the get() method immediately:
byte[] key = "key".getBytes();
byte[] value = "value".getBytes();
ProducerRecord<byte[],byte[]> record = new ProducerRecord<byte[],byte[]>("my-topic", key, value)
producer.send(record).get();
Fully non-blocking usage can make use of the Callback parameter to provide a callback that will be invoked when the request is complete.
ProducerRecord<byte[],byte[]> record = new ProducerRecord<byte[],byte[]>("the-topic", key, value);
producer.send(myRecord,
new Callback() {
public void onCompletion(RecordMetadata metadata, Exception e) {
if(e != null) {
e.printStackTrace();
} else {
System.out.println("The offset of the record we just sent is: " + metadata.offset());
}
}
});
Callbacks for records being sent to the same partition are guaranteed to execute in order. That is, in the following example callback1 is guaranteed to execute before callback2:
producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key1, value1), callback1);
producer.send(new ProducerRecord<byte[],byte[]>(topic, partition, key2, value2), callback2);
Consumer API
Automatic Offset Committing
This example demonstrates a simple usage of Kafka’s consumer api that relies on automatic offset committing.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
Setting enable.auto.commit means that offsets are committed automatically with a frequency controlled by the config auto.commit.interval.ms. The deserializer settings specify how to turn bytes into objects. For example, by specifying string deserializers, we are saying that our record’s key and value will just be simple strings.
Manual Offset Control
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
consumer.commitSync();
buffer.clear();
}
}
The committed offset should always be the offset of the next message that your application will read. Thus, when calling commitSync(offsets) you should add one to the offset of the last message processed.
try {
while(running) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.println(record.offset() + ": " + record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
} finally {
consumer.close();
}
Manual Partition Assignment
String topic = "foo";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));
Multi-threaded Processing
The Kafka consumer is NOT thread-safe. All network I/O happens in the thread of the application making the call. It is the responsibility of the user to ensure that multi-threaded access is properly synchronized. Un-synchronized access will result in ConcurrentModificationException.
public class KafkaConsumerRunner implements Runnable {
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer consumer;
public void run() {
try {
consumer.subscribe(Arrays.asList("topic"));
while (!closed.get()) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(10000));
// Handle new records
}
} catch (WakeupException e) {
// Ignore exception if closing
if (!closed.get()) throw e;
} finally {
consumer.close();
}
}
// Shutdown hook which can be called from a separate thread
public void shutdown() {
closed.set(true);
consumer.wakeup();
}
}
Then in a separate thread, the consumer can be shutdown by setting the closed flag and waking up the consumer.
closed.set(true);
consumer.wakeup();
Note that while it is possible to use thread interrupts instead of wakeup() to abort a blocking operation (in which case, InterruptException will be raised), we discourage their use since they may cause a clean shutdown of the consumer to be aborted. Detail
Kafka Streams
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.state.KeyValueStore;
import java.util.Arrays;
import java.util.Properties;
public class WordCountApplication {
public static void main(final String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("TextLinesTopic");
KTable<String, Long> wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"));
wordCounts.toStream().to("WordsWithCountsTopic", Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}
Kafka Connect
Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other systems
Features
- A common framework for Kafka connectors
- Distributed and standalone modes
- REST interface
- Automatic offset management
- Distributed and scalable by default
- Streaming/batch integration
Developing a simple connector
Developing a connector only requires implementing two interfaces, the Connector and Task. A simple example is included with the source code for Kafka in the file package. This connector is meant for use in standalone mode and has implementations of a SourceConnector/SourceTask to read each line of a file and emit it as a record and a SinkConnector/SinkTask that writes each record to a file.
public class FileStreamSourceConnector extends SourceConnector {
private String filename;
private String topic;
@Override
public Class<? extends Task> taskClass() {
return FileStreamSourceTask.class;
}
@Override
public void start(Map<String, String> props) {
// The complete version includes error handling as well.
filename = props.get(FILE_CONFIG);
topic = props.get(TOPIC_CONFIG);
}
@Override
public void stop() {
// Nothing to do since no background monitoring is required.
}
@Override
public List<Map<String, String>> taskConfigs(int maxTasks) {
ArrayList<Map<String, String>> configs = new ArrayList<>();
// Only one input stream makes sense.
Map<String, String> config = new HashMap<>();
if (filename != null)
config.put(FILE_CONFIG, filename);
config.put(TOPIC_CONFIG, topic);
configs.add(config);
return configs;
}
public class FileStreamSourceTask extends SourceTask {
String filename;
InputStream stream;
String topic;
@Override
public void start(Map<String, String> props) {
filename = props.get(FileStreamSourceConnector.FILE_CONFIG);
stream = openOrThrowError(filename);
topic = props.get(FileStreamSourceConnector.TOPIC_CONFIG);
}
@Override
public synchronized void stop() {
stream.close();
}
Working with Schemas
Schema schema = SchemaBuilder.struct().name(NAME)
.field("name", Schema.STRING_SCHEMA)
.field("age", Schema.INT_SCHEMA)
.field("admin", new SchemaBuilder.boolean().defaultValue(false).build())
.build();
Struct struct = new Struct(schema)
.put("name", "Barbara Liskov")
.put("age", 75);
There is a lot of other details but the basic overview is there.